Prima di scrivere questo thread avevo provato a riaprire questo senza successo.
Dal 18 Marzo ho continuato a studiare da autodidatta sul Purdum, cercando anche su blog e Stack. Purtroppo abito in un paesello e persone fisiche a cui chiedere e con cui scambiarsi informazioni è praticamente impossibile.
Il funzionamento del buffer e della seriale mi è ancora poco chiaro.
- Qual è il materiale che vi ha permesso meglio di capire questo argomento?
- Ho provato a studiare questo concetto, ho fatto una sorta di sunto di tutto quello che ho imparato, in grassetto ho evidenziato le parti che purtroppo faccio difficoltà a capire

Grazie per la pazienza ![]()
Da questa domanda su stack ho capito che per buffer si intende “Una parte di memoria utilizzata per conservare dei dati “. In generale è una sorta di bolla, di sacca che viene caricata in una operazione, mentre viene riempita in una o più operazioni. Un po' come il carrellino della miniera.
Un esempio in C non proprio entry level che, da quello che ho capito, serve a "costruire un buffer, è il seguente:
#define BUFSIZE 1024
char buffer[BUFSIZE];
size_t len = ;
// ... later
while((len=read(STDIN, &buffer, BUFSIZE)) > 0)
write(STDOUT, buffer, len);
Dove l'autore ha definito un buffer di 1024 byte di caratteri, che avrà quindi al suo interno 511 elementi /caratteri più l’elemento null .
Il ciclo while contiene al suo interno la funzione “read” che vuole come argomenti un canale standard di input, la reference (quindi il left value del buffer/il suo indirizzo di memoria) e la dimensione del buffer.
La condizione è “finche la lunghezza che è stata dichiarata come un size_t, un tipo intero senza segno di almeno 16 bit, è >0”
Scrivi (canale standard di output, rvalue del buffer e lunghezza)
Purtroppo non capisco perchè in lettura ci sia il left value attraverso la reference ed in scrittura un valore pass-by-value del buffer
Da questa domanda ho capito che
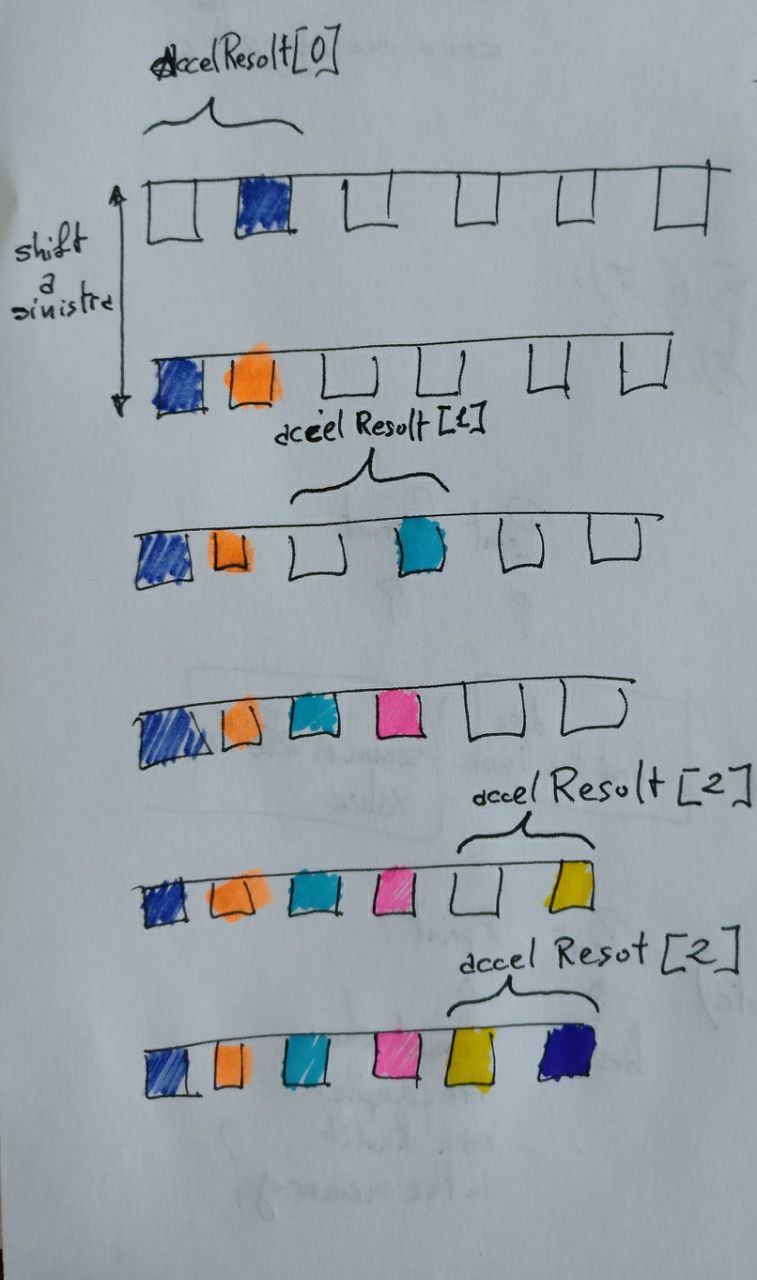
il buffer è sfruttato per la comunicazione tra il sensore gyro+acc e il microcontrollore.
In questo caso non capisco perché la funzione readFrom contenga solo due indirizzi formato Ascii e non tre (x,y,z) ne perché ci sia quel 6
//Function for reading the accelerometers
void getAccelerometerReadings(int accelResult[]) {
byte buffer[6];
readFrom(0x53,0x32,6,buffer);
accelResult[0] = (((int)buffer[1]) << 8 ) | buffer[0]; //Yes, byte order different from gyros'
accelResult[1] = (((int)buffer[3]) << 8 ) | buffer[2];
accelResult[2] = (((int)buffer[5]) << 8 ) | buffer[4];
}
Traducendo la domanda:
Il protocollo di comunicazione seriale I2C è impostato per utilizzare segmenti di informazioni di 8 bit, quindi se io voglio inviare un valore più grande di 8 bits questo deve essere scisso in più parti, e poi essere ricomposto.
(((int)buffer[0]) << 8 ) | buffer[1];
Quello che succede è che buffer [0] è convertito in un intero quindi un valore di16 bit che viene traslato di 8 bits
Questo significa che gli 8 bit nel buffer iniziale buffer [0] adesso sono localizzati in cima agli 8 bits dell’intero e gli 8 bit inferiori sono zeri.
Infine gli 8 bit inferiori sono definiti dall’operatore bitwise-or |
Che che "turn on" qualsiasi bit che era definito nel buffer [1]
Poiché la fine degli 8 bits erano 0 dalla traslazione, questo copia sempicemente il buffer [1]
(faccio fatica a capire questa affermazione
Alla fine otteniamo un valore di 16bit che contiene entrambi gli 8 bit e può essere interpretato come un numero singolo.
Grazie per aver letto fino a qui e per la pazienza ci sonon dietro tante ore di studio, ho anche un secondo thread che vorrei aprire perchè ho letto e studiato anche qui ma non ho abbastanza caratteri ![]()