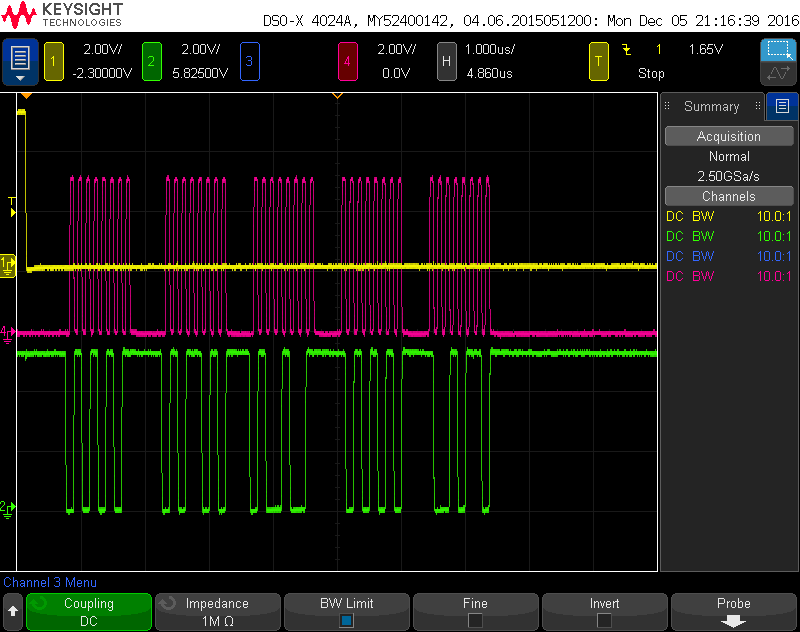
I've tidied up my test code so it can be posted here.
It's currently setup to use Pauls library (and wiznet by folder renaming), there are commented out includes at the start for changing to Ethernet2, along with lines 42-45 for the timeout and retry configuration.
The wiznet library seems the fastest of the 3, tho there is the oddity of it increasing other SPI deadtime. None of the libraries seem to be using "transfer (buffer, size);", this would boost the speed enormously without resorting to bare-metal code.
#include <SPI.h>
//#include <Ethernet2.h>
#include "Ethernet.h"
#include "w5100.h"
//#include <utility/w5500.h>
// Edit the SPI speed in C:\Users\[USERNAME]\Documents\Arduino\libraries\Ethernet2\src\utility\w5500.cpp
// to 28000000, 28MHz, line 25: (copy/paste the following is easiest)
// SPISettings wiznet_SPI_settings(28000000, MSBFIRST, SPI_MODE0);
//
// Edit occurances of SPI_CSR_DLYBCT(1) to SPI_CSR_DLYBCT(0) in
// C:\Users\[USERNAME]\AppData\Local\Arduino15\packages\arduino\hardware\sam\1.6.9\libraries\SPI\src\SPI.cpp
// and C:\Users\[USERNAME]\AppData\Local\Arduino15\packages\arduino\hardware\sam\1.6.9\libraries\SPI\src\SPI.h
//
byte mac[] = { 0xDE, 0xAD, 0xBE, 0xEF, 0xFE, 0xED };
const IPAddress MyIP( 192, 168, 0, 10 );
const IPAddress Cab1_IP (192, 168, 0, 2); //this address exists
const IPAddress Cab2_IP (192, 168, 0, 1); //this doesn't, for testing retry and timeout
unsigned int local_Port = 12345;
unsigned int Cab1_Port = 12345;
unsigned int Cab2_Port = 12345;
EthernetUDP Udp;
const int EthTxBuf_Size = 100;
byte EthTxBuf[EthTxBuf_Size];
byte EthRxBuf[EthTxBuf_Size];
unsigned long current_micros;
const unsigned long looptime = 2000;
const int Testpin = 52;
const int Errorpin = 22;
const int Framepin = 32;
const int FPGA_SPIpin = 4;
void setup()
{
Ethernet.begin(mac,MyIP);
Udp.begin(local_Port);
pinMode(Testpin, OUTPUT);
pinMode(Errorpin, OUTPUT);
pinMode(Framepin, OUTPUT);
pinMode(FPGA_SPIpin, OUTPUT);
//w5500.setRetransmissionCount(1);
//w5500.setRetransmissionTime(1);
W5100.setRetransmissionCount(uint8_t(1));
W5100.setRetransmissionTime(uint16_t(1));
}
void loop()
{
current_micros = micros();
for (byte j=0; j<EthTxBuf_Size; j++)
{
EthTxBuf[j] = j;
}
digitalWrite(Framepin, HIGH);
digitalWrite(Framepin, LOW);
digitalWrite(Testpin, HIGH);
Udp.beginPacket(Cab1_IP, Cab1_Port);
Udp.write(EthTxBuf, EthTxBuf_Size);
if (Udp.endPacket() == 0)
{
digitalWrite(Errorpin, HIGH);
digitalWrite(Errorpin, LOW);
}
digitalWrite(Testpin, LOW);
for (byte j=0; j<EthTxBuf_Size; j++)
{
EthTxBuf[j] = j;
}
SPI.beginTransaction(SPISettings(28000000, MSBFIRST, SPI_MODE0));
digitalWrite(FPGA_SPIpin, LOW);
SPI.transfer (&EthTxBuf, EthTxBuf_Size);
digitalWrite(FPGA_SPIpin, HIGH);
SPI.endTransaction();
digitalWrite(Testpin, HIGH);
Udp.beginPacket(Cab2_IP, Cab2_Port);
Udp.write(EthTxBuf, EthTxBuf_Size);
if (Udp.endPacket() == 0)
{
digitalWrite(Errorpin, HIGH);
digitalWrite(Errorpin, LOW);
}
digitalWrite(Testpin, LOW);
while ((micros()- current_micros)<looptime)
{
}
}