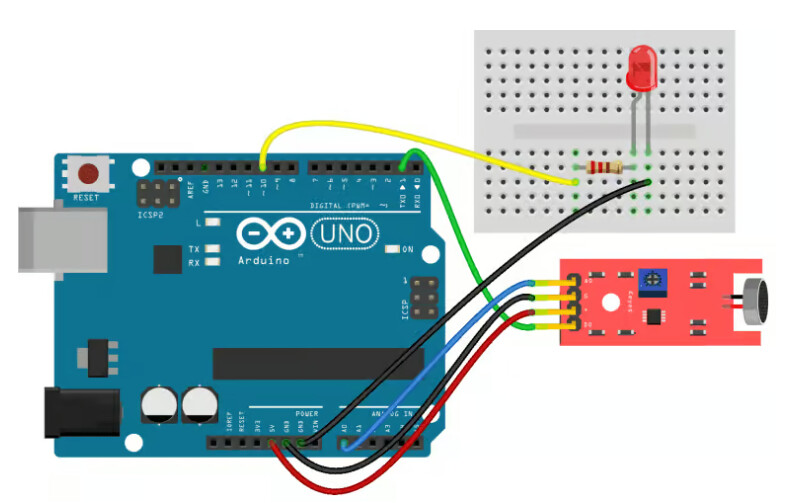
Hi guys, I'm working on a project using this sound module connected to an Arduino Uno:
Link
However it is not working properly, even when I wired it correctly according to this website:
Website
I checked it a lot to ensure I wired it correctly so I don't think that's the issue.
Heres the original code I ran that didn't work:
#define SOUND_INPUT A0
#define SOUND_TRIGGER 7 // still used for presence detection if needed
const byte MAX_USERS = 3;
const unsigned int RECORD_DURATION = 7000; // 7 seconds
const unsigned int LOGIN_DURATION = 15000; // 15 seconds
const byte SLICE_DURATION = 150; // Check every 150 ms
const byte ID_LENGTH = 15; // Max characters per ID
const byte RECORD_SLICES = RECORD_DURATION / SLICE_DURATION; // 46
const int LOGIN_SLICES = LOGIN_DURATION / SLICE_DURATION; // 100
const int MATCH_TOLERANCE = 100; // Allowed deviation per sample when matching
// Store analog sound patterns and user IDs
int userPatterns[MAX_USERS][RECORD_SLICES];
char userIDs[MAX_USERS][ID_LENGTH];
byte userCount = 0;
void setup() {
Serial.begin(9600);
while (!Serial);
Serial.println("Voice Recognition Simulation Ready.");
}
void loop() {
Serial.println("Type '1' to register or '2' to login:");
while (!Serial.available());
char option = Serial.read();
while (Serial.available()) Serial.read(); // flush extras
if (option == '1') {
registerUser();
} else if (option == '2') {
loginUser();
} else {
Serial.println("Invalid option. Try again.");
}
}
void registerUser() {
if (userCount >= MAX_USERS) {
Serial.println("User limit reached.");
return;
}
Serial.println("Prepare to speak. Recording in 3 seconds...");
delay(3000);
Serial.println("Recording now for 7 seconds...");
for (int i = 0; i < RECORD_SLICES; i++) {
userPatterns[userCount][i] = analogRead(SOUND_INPUT);
Serial.println(SOUND_INPUT);
delay(SLICE_DURATION);
}
Serial.println("Recording complete.");
Serial.println("Enter a user ID to associate (max 14 characters):");
// Flush buffer and wait for clean input
while (Serial.available()) Serial.read();
while (!Serial.available());
readLine(userIDs[userCount], ID_LENGTH);
Serial.print("User registered with ID: ");
Serial.println(userIDs[userCount]);
userCount++;
}
void loginUser() {
Serial.println("Prepare to speak. Listening in 3 seconds...");
delay(3000);
Serial.println("Listening for 15 seconds...");
int loginPattern[LOGIN_SLICES];
unsigned long startTime = millis();
for (int i = 0; i < LOGIN_SLICES; i++) {
loginPattern[i] = analogRead(SOUND_INPUT);
Serial.println(SOUND_INPUT);
delay(SLICE_DURATION);
}
unsigned long endTime = millis();
float timeSpentSeconds = (endTime - startTime) / 1000.0;
Serial.print("Actual listening time: ");
Serial.print(timeSpentSeconds, 2);
Serial.println(" seconds");
Serial.println("Listening complete.");
Serial.println("Enter user ID to attempt login:");
while (Serial.available()) Serial.read();
while (!Serial.available());
char inputID[ID_LENGTH];
readLine(inputID, ID_LENGTH);
Serial.print("Attempting login with ID: ");
Serial.println(inputID);
int userIndex = -1;
for (int i = 0; i < userCount; i++) {
if (strcmp(userIDs[i], inputID) == 0) {
userIndex = i;
break;
}
}
if (userIndex == -1) {
Serial.println("User ID not found.");
return;
}
// Attempt to find matching 7s pattern within 15s login window
bool match = false;
for (int i = 0; i <= LOGIN_SLICES - RECORD_SLICES; i++) {
bool windowMatch = true;
for (int j = 0; j < RECORD_SLICES; j++) {
int diff = abs(loginPattern[i + j] - userPatterns[userIndex][j]);
if (diff > MATCH_TOLERANCE) {
windowMatch = false;
break;
}
}
if (windowMatch) {
match = true;
break;
}
}
if (match) {
Serial.println("Login successful!");
} else {
Serial.println("Login failed: Pattern mismatch.");
}
}
// Reads a full line of serial input into a char array
void readLine(char* buffer, byte length) {
byte i = 0;
while (true) {
if (Serial.available()) {
char c = Serial.read();
if (c == '\n' || c == '\r') {
buffer[i] = '\0';
break;
}
if (i < length - 1) {
buffer[i++] = c;
}
}
}
}
Heres the result I got in the serial monitor after I ran it:
"Voice Recognition Simulation Ready.
Type '1' to register or '2' to login:
(I typed 1)
Prepare to speak. Recording in 3 seconds...
Recording now for 7 seconds...
14
14
14
14
14
14
14
14...
Recording complete.
Enter a user ID to associate (max 14 characters):
(I typed ID #1)
User registered with ID: ID #1
Type '1' to register or '2' to login:
(I typed 2)
Prepare to speak. Listening in 3 seconds...
Listening for 15 seconds...
14
14
14
14
14
14
14
14
14
14
14
Actual listening time: 15.02 seconds
Listening complete.
Enter user ID to attempt login:
(I typed ID #1)
Attempting login with ID: ID #1
Login successful!
Type '1' to register or '2' to login: "
As you can see, the repetitive 14's are an issue. Ive eliminated a significant part of the issue to be the sound module and not the code because when I ran this simple sketch:
const int microphonePin = A0;
void setup() {
Serial.begin(9600);
}
void loop() {
int val = analogRead(microphonePin);
Serial.println(val);
delay (1000);
}
These are the readings I got in the serial monitor:
"13
12
13
13
12
12
12
13
12
12
12
13
12"
In that time frame, I screamed, slammed the table and did all sorts of things but couldn't get a huge difference in the readings. When I unplugged it however I got these readings:
"224
338
377
414
448
476"
Which was a huge jump from before.
For context, my goal with the sound module is to distinguish between different human voices by assigning each user ID a list of numerical values that represent the voltage fluctuations caused by their voice saying the same word from the same distance. The system listens for 15 seconds to give me some buffer time, and within that interval, it checks if any 7-second segment matches the 7-second voice pattern associated with the ID I'm trying to log in with. If a match is found, it's considered a successful identification.
From my research, I realize this method is quite unreliable due to the lack of precision and accuracy—this module is essentially just a basic sound detector. Still, it's a starting point that helps me ease into the process without jumping straight into complex solutions. Eventually, I plan to move on to more advanced hardware. That said, if anyone has suggestions for alternative modules that are better suited for voice recognition, I’d be glad to hear them—I'd much rather invest time in learning a more capable tool than spend it troubleshooting something that's ultimately limited and just a dead end.